core链上提币操作(链上提币多久到账)
大数据究竟是什么?大数据有哪些技术呢?
大数据包括结构化、半结构化和非结构化数据,非结构化数据越来越成为数据的主要部分。据IDC的调查报告显示:企业中80%的数据都是非结构化数据,这些数据每年都按指数增长60%。 [6] 大数据就是互联网发展到现今阶段的一种表象或特征而已,没有必要神话它或对它保持敬畏之心,在以云计算为代表的技术创新大幕的衬托下,这些原本看起来很难收集和使用的数据开始容易被利用起来了,通过各行各业的不断创新,大数据会逐步为人类创造更多的价值。
想要系统的认知大数据,必须要全面而细致的分解它,着手从三个层面来展开:
第一层面是理论,理论是认知的必经途径,也是被广泛认同和传播的基线。在这里从大数据的特征定义理解行业对大数据的整体描绘和定性;从对大数据价值的探讨来深入解析大数据的珍贵所在;洞悉大数据的发展趋势;从大数据隐私这个特别而重要的视角审视人和数据之间的长久博弈。
第二层面是技术,技术是大数据价值体现的手段和前进的基石。在这里分别从云计算、分布式处理技术、存储技术和感知技术的发展来说明大数据从采集、处理、存储到形成结果的整个过程。
第三层面是实践,实践是大数据的最终价值体现。在这里分别从互联网的大数据,政府的大数据,企业的大数据和个人的大数据四个方面来描绘大数据已经展现的美好景象及即将实现的蓝图。

大数据 big data 国标定义:
支持一个或多个应用领域,按概念结构组织的数据集合,其概念结构描述这些数据的特征及其对
应实体间的联系。具有数量巨大、种类多样、流动速度快、特征多变等特征,并且难以用传统数据体
系结构和数据处理技术进行有效组织、存储、计算、分析和管理的数据集。
[来源:GB/T 35274-2017,定义3.1]
1、基础概念
大数据是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。大数据技术则主要用来解决海量数据的存储和分析。
2、特点分析
大数据的5V特点(IBM提出):Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性)。
3、发展过程
Google在2004年前后发表的三篇论文,分别是文件系统GFS、计算框架MapReduce、NoSQL数据库系统BigTable。海量数据文件,分析计算,并存储,确立了大数据的基本原理和思路。
天才程序员DougCutting,也是Lucene、Nutch项目发起人。根据Google论文原理初步实现类似GFS和MapReduce的功能,后来发展成为大名鼎鼎的Hadoop。
再后来,Hadoop经过高速的发展,已经形成一个生态体系,基于Hadoop之上,有实时计算,离线计算,NoSQL存储,数据分析,机器学习等一系列内容。
从这一系列事情发展看技术规律:Google业务实践中创造性的提出论文作为基础,业务的成长和需求,迫使技术不断更新换代。所以业务是技术不断发展的关键。
我有幸做了有五六七八年的大数据吧,谈谈自己的看法。简单来说,就是现在各个APP,网站产生的数据越来越多,越来越大,传统的数据库比如MySQL Oracle之类的,已经处理不过来了。所以就产生了大数据相关的技术来处理这些庞大的数据。
第一,首先要把这些大数据都可靠的存储起来,经过多年的发展,hdfs已经成了一个数据存储的标准。
第二,既然有了这么多的数据,我们可以开始基于这些数据做计算了,于是从最早的MapReduce到后来的hive,spark,都是做批处理的。
第三, 由于像hive这些基于MapReduce的引擎处理速度过慢,于是有了基于内存的olap查询引擎,比如impala,presto。
第四,由于批处理一般都是天级别或者小时级别的,为了更快的处理数据,于是有了spark streaming或者flink这样的流处理引擎。
第五,由于没有一个软件能覆盖住所有场景。所以针对不同的领域,有了一些特有的软件,来解决特定场景下的问题,比如基于时间序列的聚合分析查询数据库,inflexdb opentsdb等。采用预聚合数据以提高查询的druid或者kylin等,
第六,还有其他用于数据削峰和消费订阅的消息队列,比如kafka和其他各种mq
第七,还有一些其他的组件,比如用于资源管理的yarn,协调一致性的zookeeper等。
第八,由于hdfs 处理小文件问题不太好,还有为了解决大数据update和insert等问题,引入了数据湖的概念,比如hudi,iceberg等等。
第九,业务方面,我们基于大数据做一些计算,给公司的运营提供数据支撑。做一些推荐,给用户做个性化推荐。机器学习,报警监控等等。
附一张大数据技术图谱,从网上找的

就以悟空问答为例说说大数据的故事。以下说的数字都不是真实的,都是我的假设。
比如每天都有1亿的用户在悟空问答上回答问题或者阅读问答。
每天产生的内容
假设平均有1000万的用户每天回答一个问题。一个问题平均有1000的字, 平均一个汉字占2个字节byte,三张图片, 平均一帐图片300KB。那么一天的数据量就是:
文字总量:10,000,000 * 1,000 * 2 B = 20 GB
图片总量: 10,000,000 * 3 * 300KB = 9 TB
为了收集用户行为,所有的进出悟空问答页面的用户。点击,查询,停留,点赞,转发,收藏都会产生一条记录存储下来。这个量级更大。
所以粗略估计一天20TB的数据量. 一般的PC电脑配置大概1TB,一天就需要20台PC的存储。
如果一个月的,一年的数据可以算一下有多少。传统的数据库系统在量上就很难做到。
另外这些数据都是文档类型的数据。需要各种不同的存储系统支持,比如NoSQL数据库。
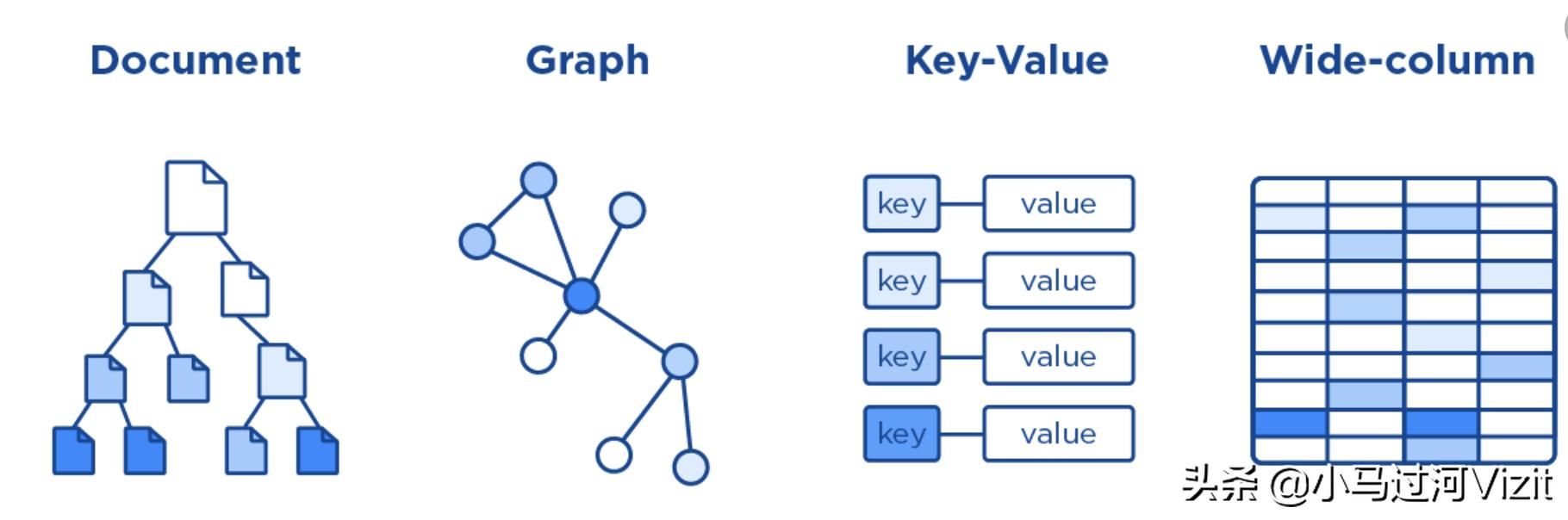
需要分布式数据存储,比如Hadoop的HDFS。

数据的流动
上述1000万个答案,会有1亿的人阅读。提供服务的系统成百上千。这些数据需要在网上各个系统间来回传播。需要消息系统比如Kafka。
在线用户量
同时在线的用户量在高峰时可能达到几千万。如此高的访问量需要数前台服务器同时提供一致的服务。为了给用户提供秒级的服务体现,需要加缓存系统比如redis。
机器学习,智能推荐
所有的内容包括图片都会还用来机器学习的分析,从而得到每个用户的喜好,给用户推荐合适的内容和广告。还有如此大量的数据,必须实时的分析,审核,审核通过才能发布,人工审核肯定做不到,必须利用机器来智能分析,需要模式识别,机器学习,深度学习。实时计算需要Spark,Flink等流式计算技术。
服务器的管理
几千台服务器,协同工作。网络和硬件会经常出问题。这么多的资源能够得到有效利用需要利用云计算技术,K8S等容器管理工具。还需要分布式系统的可靠性和容灾技术。
本人,@小马过河Vizit,专注于分布式系统原理和实践分享。希望利用动画生动而又准确的演示抽象的原理。欢迎关注。
关于我的名字。小马过河Vizit,意为凡事像小马过河一样,需要自己亲自尝试,探索才能获得乐趣和新知。Vizit是指Visualize it的缩写。一图胜千言,希望可以利用动画来可视化一些抽象的原理。
近几年,大数据的概念逐渐深入人心,大数据的趋势越来越火爆。但是,大数据到底是个啥?怎么样才能玩好大数据呢?
大数据的基本含义就是海量数据,麦肯锡全球研究所给出的定义是:一种规模大到在获取、存储、管理、分析方面大大超出了传统数据库软件工具能力范围的数据集合,具有海量的数据规模、快速的数据流转、多样的数据类型和价值密度低四大特征。
数字经济的要素之一就是大数据资源,现在大家聊得最多的大数据是基于已经存在的大数据的应用开发。
如今,大数据技术已应用在各行各业。小麦举个例子,讲述一下最贴近我们生活的民生服务是如何运用大数据。
最近电视新闻提及到的“一网统管”精准救助场景,传统的救助方式往往通过困难家庭申请、审核、审批等多项程序,遇到需要跨部门、跨层级、跨街区协调解决的个案,还需要召开各级协调会的形式协商解决。
现在通过“精准救助”的方式,民政部门在平时的摸排中了解情况,将相关信息录入到“一网统管”数据中心,再根据数据模型识别出需要协助的家庭,随后形成走访工单派发给社工对其进行帮扶,从而提升救助的效率,做到雪中送炭。
在数字化政府改造之前,每个部门只掌握各自分管的数据,形成“信息孤岛”;有了大数据分析平台后,所有的数据信息,便打通了“任督二脉”。

政府可以充分利用大数据技术打造“一网统管”精准救助场景,极大提升了社会救助的科学性和精准性,让城市变得更加温暖。
core币如何质押教程?
答:core币如何质押教程步骤如下,第一步打开:节点质押地址。
第二步:找到21个节点,挑选一个质押,不要找那种小节点,节点掉线会扣你的奖励,最好找官方节点。
第三步:点质押,输入数量即可。